
科研服务
立足于生命科学,为基础研究领域科学工作者提供生物学高端技术服务
瑞源生物
相关产品

- 产品描述
-
服务描述:
蛋白质与核酸的相互作用是研究基因表达调控机制的关键,传统实验中常采用DNA Pull Down等方法进行验证,但实验操作复杂且可能无法捕获所有相关蛋白质。
基于此我们利用AI智能技术构建了高效的数字化高通量筛选体系。该服务可快速实现对海量蛋白质或核酸序列的精准建模、互作预测与优化筛选,能够全面筛选并预测可能的核酸-蛋白质相互作用,并提供结构层面的详细信息,极大缩短实验周期,降低实验成本。
应用领域
DNA结合蛋白与核酸互作分析
转录因子与启动子互作分析
技术优势
高精度筛选:全新引入HDOCK的核酸对接专长,与AlphaFold3的权威复合物进行预测
高通量初筛:储备100+物种的全基因组数字文库,20+物种的转录因子文库,可直接开展筛选,高通量筛选上万个蛋白,节约等待时间
高质量图片:精品版服务提供五组蛋白三维模型(远景+近景)结合位点分析图,清晰展示结合位点、氢键及距离信息,提供全面的互作细节
全链路实验保障:依托自有实验平台,提供酵母单杂、双荧光素酶等各类湿实验,提供从数字化筛选到一对一验证的全流程服务
服务流程

样品接受标准
样本
要求
备注
基因序列
需提供CDS文件
若数据库版本要求请说明
服务流程、周期及交付
精品版:
服务流程 工作日 交付材料 客户下单 14个 1、三轮筛选(HDOCK初筛、HDOCK细筛、AlphaFold3精筛)全数据Excel表(包括基因编号、建模评分、互作分值)
2、五对结合位点分析图
3、详细的实验报告
诱饵基因建模分析 HDOCK初筛、细筛对接评估 30对AlphaFold3一对一预测 5对精细互作分析 数据整理和分析 普通版:
服务流程 工作日 交付材料 客户下单 10个 1、三轮筛选(HDOCK初筛、HDOCK细筛、AlphaFold3精筛)全数据Excel表(包括基因编号、建模评分、互作分值)
2、详细的实验报告
诱饵基因建模分析 HDOCK初筛、细筛对接评估 30对AlphaFold3一对一预测 数据整理和分析 案例报告
1、诱饵基因的三维核酸建模:

图:诱饵基因三维结构
2、HDock快速对接:
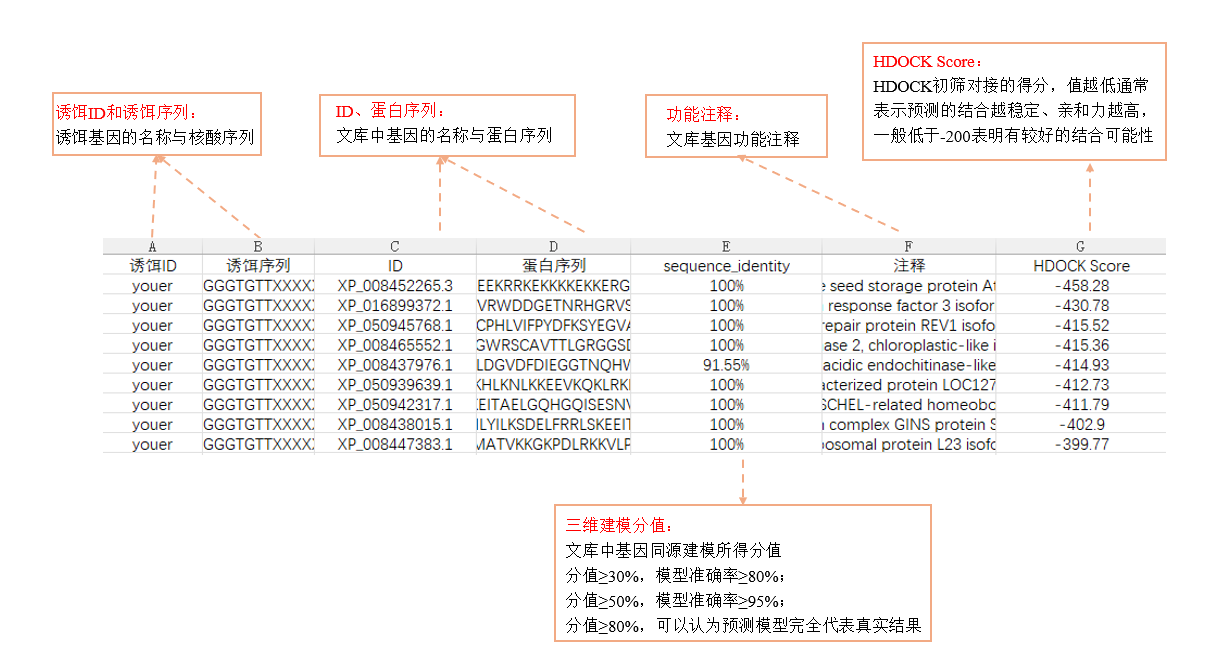
图: 第一轮筛选所得结果
3、HDock默认对接:根据第一轮HDOCK的打分排序,选取打分前200的互作对,使用HDOCK默认参数进行精筛。

图:第二轮筛选所得结果
4、AlphaFold3对接:AlphaFold3模型进行了批量对接,对可能为假阳性的预测结果以及想要重点关注的蛋白核酸互作对详细分析。
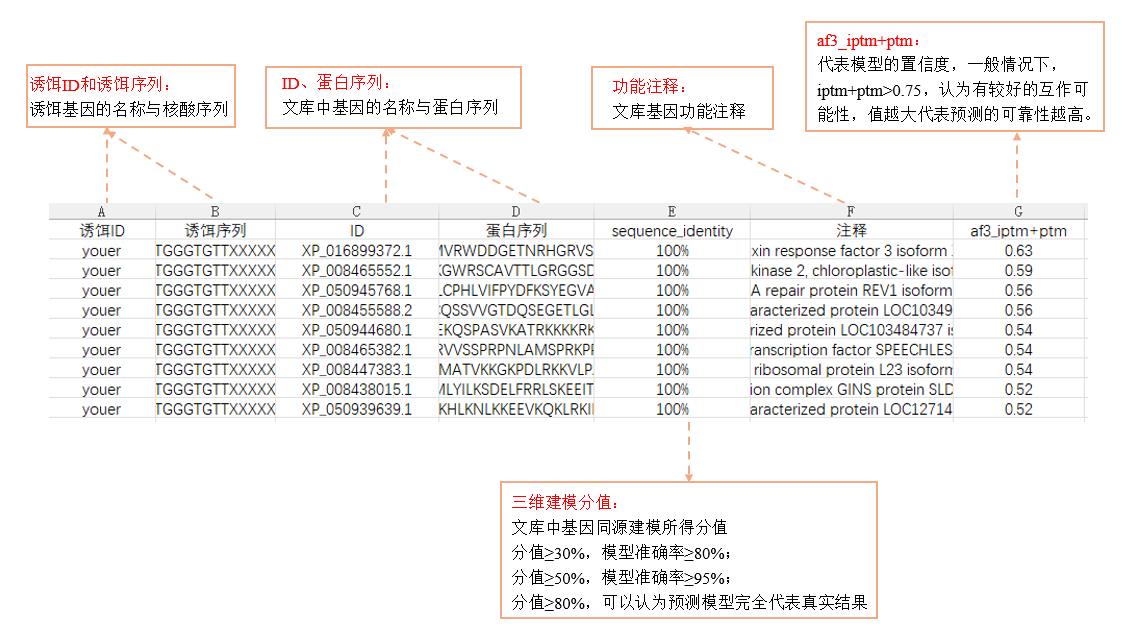
图:第三轮筛选所得结果
5、结合位点分析(精品版):将iptm+ptm得分最高的前五对蛋白核酸复合物作为互作可能性最高的结构,用pymol进行互作界面的分析。
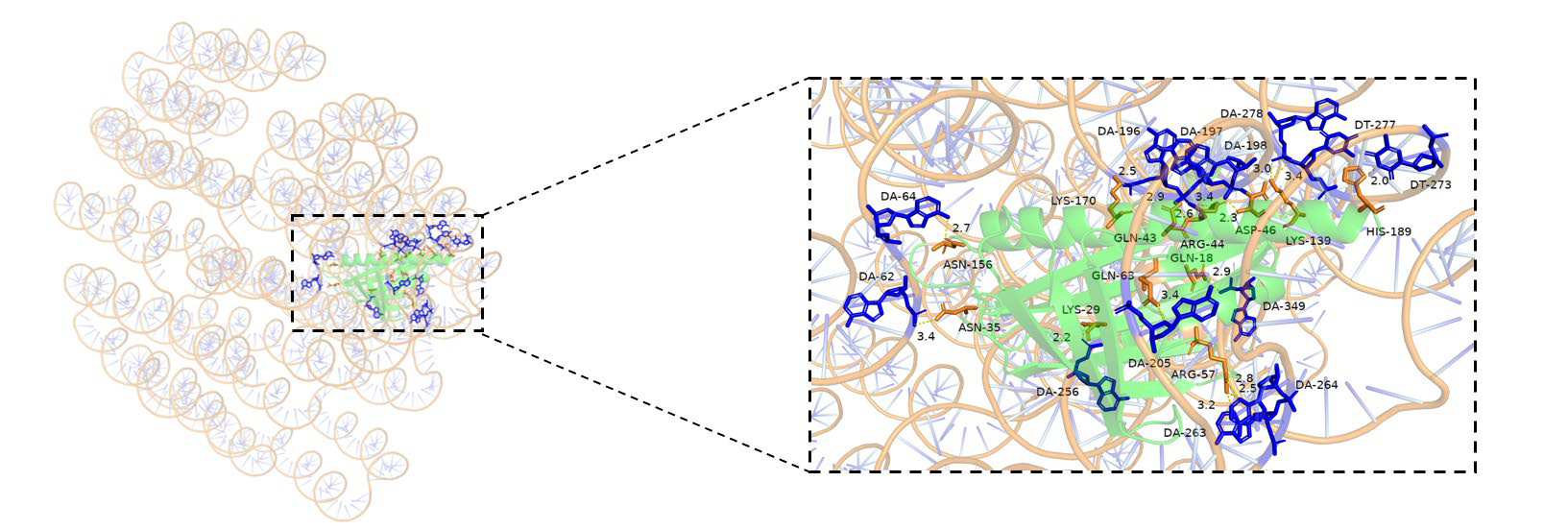
图: 蛋白与核酸关键残基互作图
参考文献
[1] Zhang X, Mei LC, Gao YY, Hao GF, Song BA. Web tools support predicting protein-nucleic acid complexes stability with affinity changes. Wiley Interdiscip Rev RNA. 2023 Sep-Oct;14(5):e1781. doi: 10.1002/wrna.1781. Epub 2023 Jan 24. PMID: 36693636.
[2] Abramson, J., Adler, J., Dunger, J. et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature 630, 493–500 (2024).
声明:本公司出售产品只能用于科研目的,不得用于诊断或者治疗!

